随着AI在各个领域的持续深入应用,AI技术与传统行业不断的融合,智能时代成为世界新起点。而城市大脑、安防视频结构化、人脸识别、智慧制造、金融建模、智能机器人、新材料发现、脑神经科学、医学影像分析等,人工智能时代的科学研究和工程实践都极度依赖计算力的支持。
在智能安防相关项目中,由于摄像头数量巨大、品牌庞杂、同一路图像需要多种结构化分析、结构化前端可执行的结构化内容有限、非结构化数据量大等问题,大多数用户仍然主要依靠后端进行数据结构化处理。
今天我们给大家带来的是一款全新的依托国产AI芯片设计的超强算力云端AI计算加速卡,比特大陆算丰SC5+,其在评测中体现出的高算力、高性能功耗比、强劲视频解码能力、全链路加速能力、友好的工具链等诸多让人眼前一亮的特性,都使得该设备成为一款云端AI计算基础设施的上佳选择。
标准规范设计 广泛兼容适配
此次测试编辑拿到手上的比特大陆算丰SC5+云端AI计算加速卡外观设计简约大气,采用标准半高半长尺寸设计,通过实物比较,该加速卡和英伟达的P4、T4等是同一规格尺寸,据比特大陆技术人员介绍,该加速卡还可以和英伟达的P4、T4等在同一台算力服务器中混合使用,充分地考虑了客户的利旧应用。

和华为Atlas300 AI加速卡的设计很相似,SC5+加速卡上搭载了3颗比特大陆自研的BM1684高性能计算芯片,该芯片已经是比特大陆最近三年中推出的第三代云端AI芯片,其可靠性和稳定性都已经得到了充分的市场验证和认可。
另外,该加速卡还可适配各类x86服务器,国产CPU系统如飞腾、申威、兆芯等;适配各类主流Linux操作系统(CentOS/Ubuntu /Debian),包括国产麒麟、Deepin;同时算丰SC系列加速卡产品也是国内首批支持百度PaddlePaddle深度学习开源框架的硬件产品之一。在2020年3月,百度的Paddle Lite推理开源框架宣布和比特大陆实现全面适配。
令人惊喜的澎湃算力
天下武功,唯快不破。对安防各类以视频、图片为核心AI分析要素的业务场景而言,每秒的图片吞吐量(image/second)指标至关重要,这意味着单张云端加速卡最大的峰值AI分析处理能力指标越高算力越强。
从标称算力来看,该加速卡可提供高达105.6T INT8算力(Winograd 加速器打开的条件下),以及6.6T FP32算力,支持高精度的浮点计算和大容量的整型数值计算。
a&s此次选择了评价AI芯片最常用的RESNET50开源模型,采用业界通用的ImageNet标准的公开数据集(5万张图片),在SC5+加速卡标称最强的INT8计算性能上进行了实跑测试。在INT8,RESNET 50,Batch=4条件下SC5+图片吞吐性能达到3000+ image/second,超过NVIDIA T4约10%。其他各类模型下的吞吐性能也同样超过T4(如下图)。在Mobilenet v1模型下,SC5+的吞吐性能则更是达到了惊人的9000张以上。
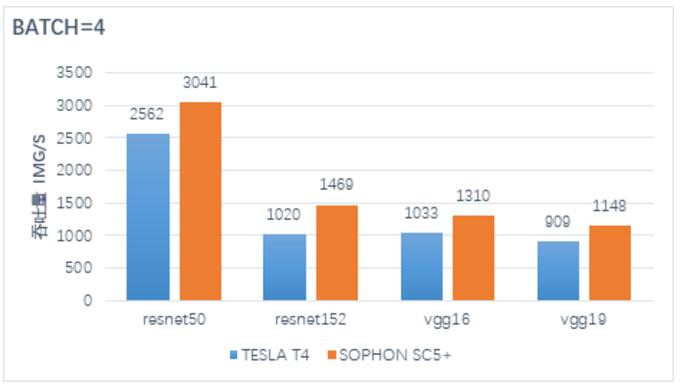
超高算力获得比
内外兼修,方成高手。通过计算得知,SC5+加速卡在VGG16等模型下的实际算力输出可以达到70T以上,这意味着其所使用的BM1684芯片的实际利用率达到了惊人的75%以上,相比之下,英伟达GPU的利用率则处于40%-50%的区间。
以VGG19算力性能实测为例:
初始设置:输入人脸图片数量为50,000张(分辨率为224×224,RGB 3通道模式),线程数为3;计算精度:整数数据计算INT8;
VGG19模型设置:
基于Caffe 1.0.0-rc3(Convolutional Architecture for Fast Feature Embedding,卷积神经网络框架),Batch Size为32,其余为配置文件默认参数,模型单次运行所消耗的算力为39.26Gops;
通过上述环境配置,可以精确计算出,在进行标准的VGG19模型运算时,SC5+加速卡输出的实际算力为75.2T。
换句话说,虽然英伟达的GPU标称算力指标远远高于比特大陆提供的SC5+加速卡,而通过实测得出的结论来看,实际的算力获得比显然是比特大陆遥遥领先,由此也可以看出比特大陆的AI芯片架构设计确实有其独到之处。对最终客户来说,同样花一块钱,实际获得的算力远远超过同类产品,相信所有的客户都会愿意自己花费真金白银买到的是实际算力而非是纸面上标称很高的算力指标。
优势尽显的性能功耗比
同样的,在性能功耗比方面,单位功耗下的SC5+输出实际算力超出NVIDIA T4的指标接近一倍,证明SOPHON AI芯片框架的能效比优势明显(如下图)。
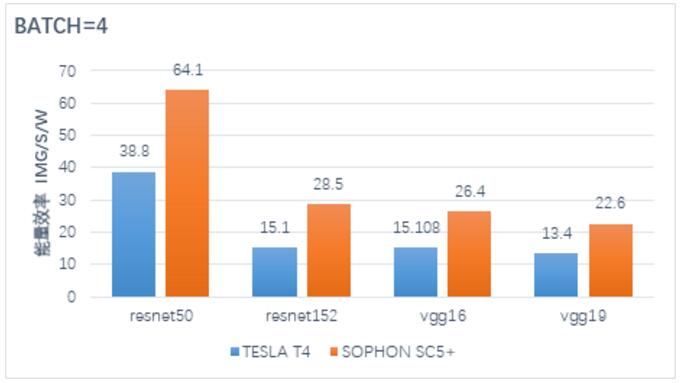
性能功耗比:TESLA T4 vs SC5+
强大的视频解码能力
对安防应用场景而言,大量高清网络视频流的接入是最普遍应用的场景,摄像头的图像格式更是与日俱新,不断提升,从200万,300万,500万,到现在的800万乃至千万级像素的网络摄像机已经开始应用,AI解析首先需要对这些超高分辨率的视频或者图像进行解码还原,再进行各类AI算法的解析计算。
SC5+具备高达2880fps,约合114路1080P@25fps高清视频流的硬解码能力,堪称国产解码能力最强的AI加速卡。最大解码分辨率可支持到8K级别(半实时)。
在图片解码能力方面,SC5+单卡具备1440 img/s以上的图片解码能力。最大图片解码分辨率可以达到32768*32768 pixels。这使得SC5+ 在解析某些超大型的拼接图像时,如工业流水线的长画幅连续检测图像、高分辨率全景摄像机生成的多画面拼接图像等,具备充足的解码能力。
高度可扩展的视频转码能力
SC5+具备支持将接入的全部视频资源转换为不低于32Kbps低码流(25帧、CIF分辨率)和不低于1Mbps高码流(25帧)两种符合H.264标准的码流。并可随板卡的数量增加进行线性扩展,支持超大容量的视频接入转码。
视频转码功能在当前主流AI加速卡上并不多见,对于视频上云需求越来越普遍而带宽条件又不能满足需求的视频大联网系统,比如高速公路、电力、森林防火等跨地域分散广密度低的视频监控场景,SC5+ AI加速卡无疑是非常好的选择。
人脸识别算法实测性能强大


简单易上手的系统软件
产品特色
点评
重要规格参数



